Basic Latin, Diacritical Marks & IMDB
Latest update:
This is a story of not placing trust in public libraries.
The IMDB website has an auto-complete input element. While its
mechanism isn't documented anywhere, you can easily explore it with
curl:
$ alias labels='json d | json -a l'
$ imdb=https://v2.sg.media-imdb.com/suggestion
$ curl -s $imdb/a/ameli.json | labels
Amélie
Amelia Warner (I)
Austin Amelio
Amelia Clarkson
Amelia Rose Blaire
Amelia Heinle
Amelia Bullmore
Amelia Eve
The endpoint understands acute accents & strokes:
$ curl -s $imdb/b/boże+ciało.json | labels
Corpus Christi
Corpus Christi
Olecia Obarianyk
Alecia Orsini Lebeda
Zwartboek: The Special
The Cult: Edie (Ciao Baby)
Anne-Marie: Ciao Adios
The C.I.A.: Oblivion
(Corpus Christi is the translation of Boże Ciało.)
The funny part starts when you try to enter the same string (boże
ciało) in the input field on the IMDB website:
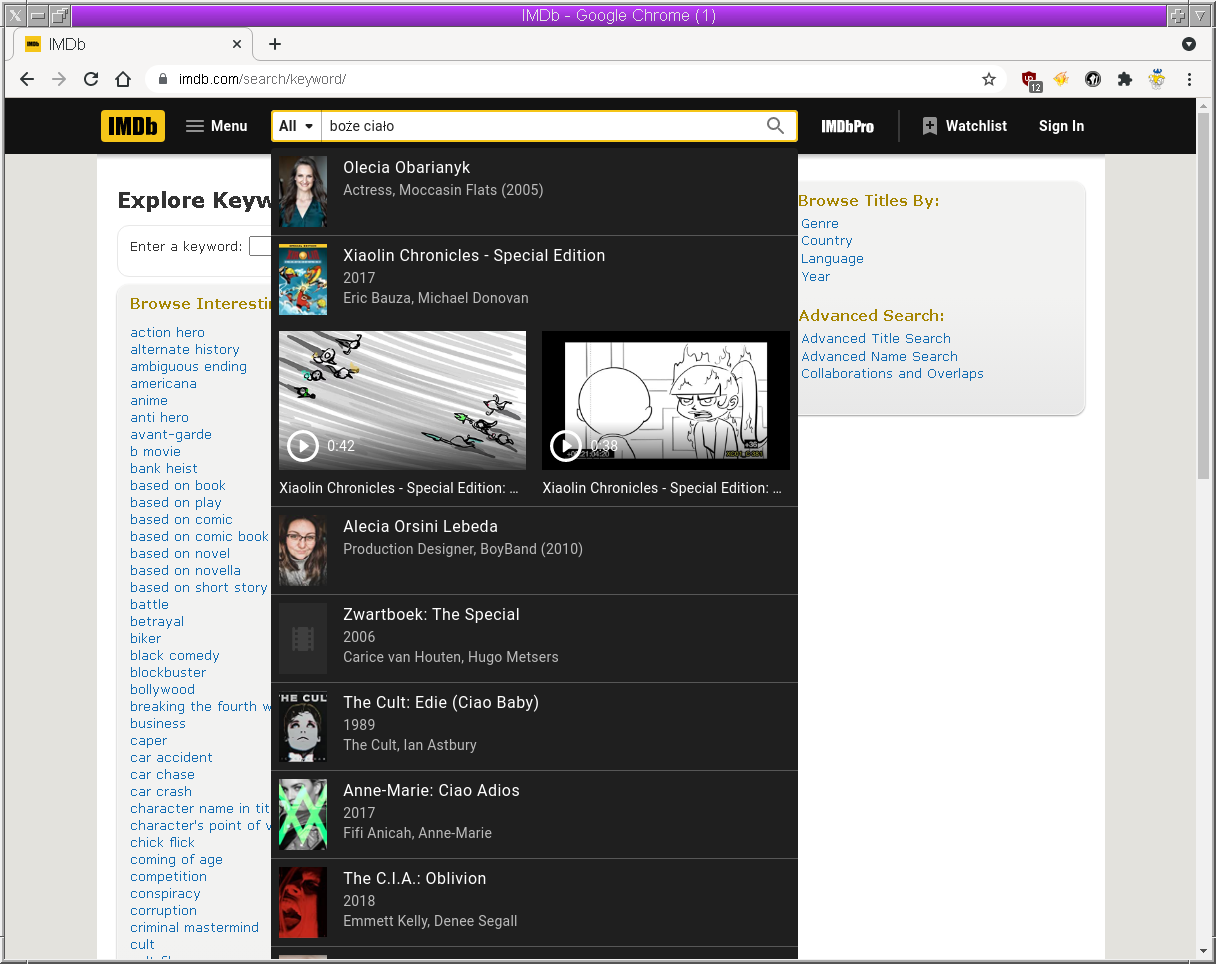
Where's the movie? Turns out, the actual query that a page makes looks
like
https://v2.sg.media-imdb.com/suggestion/b/boe_ciao.json
boe_ciao? Apparently, it tried to convert the string to a basic
latin set, replacing spaces with an undescore along the way. It's not
terribly hard to spot a little problem here.
This is the actual function that does the convertion:
var ae = /[àÀáÁâÂãÃäÄåÅæÆçÇèÈéÉêÊëËìÍíÍîÎïÏðÐñÑòÒóÓôÔõÕöÖøØùÙúÚûÛüÜýÝÿþÞß]/
, oe = /[àÀáÁâÂãÃäÄåÅæÆ]/g
, ie = /[èÈéÉêÊëË]/g
, le = /[ìÍíÍîÎïÏ]/g
, se = /[òÒóÓôÔõÕöÖøØ]/g
, ce = /[ùÙúÚûÛüÜ]/g
, ue = /[ýÝÿ]/g
, de = /[çÇ]/g
, me = /[ðÐ]/g
, pe = /[ñÑ]/g
, fe = /[þÞ]/g
, be = /[ß]/g;
function ve(e) {
if (e) {
var t = e.toLowerCase();
return t.length > 20 && (t = t.substr(0, 20)),
t = t.replace(/^\s*/, "").replace(/[ ]+/g, "_"),
ae.test(t) && (t = t.replace(oe, "a").replace(ie, "e")
.replace(le, "i").replace(se, "o")
.replace(ce, "u").replace(ue, "y")
.replace(de, "c").replace(me, "d")
.replace(pe, "n").replace(fe, "t").replace(be, "ss")),
t = t.replace(/[\W]/g, "")
}
return ""
}
(It took me some pains to extract it from god-awful obfuscated mess
that IMDB returns to browsers.)
It's not only the Polish folks whose alphabet gets mangled. The Turks
are out of luck too:
ve('Ruşen Eşref Ünaydın') // => ruen_eref_unaydn
I say the function above sometimes does its job rather wrong:
ve('ąśćńżółıźćę') // => o
deburr() from lodash is available publicly since February 5, 2015 &,
unlike the forlorn IMDB attempt, works fine:
deburr('Boże Ciało') // => Boze Cialo
deburr('Ruşen Eşref Ünaydın') // => Rusen Esref Unaydin
deburr('ąśćńżółıźćę') // => ascnzolizce
Why not use it?
Tags: ойті
Authors: ag